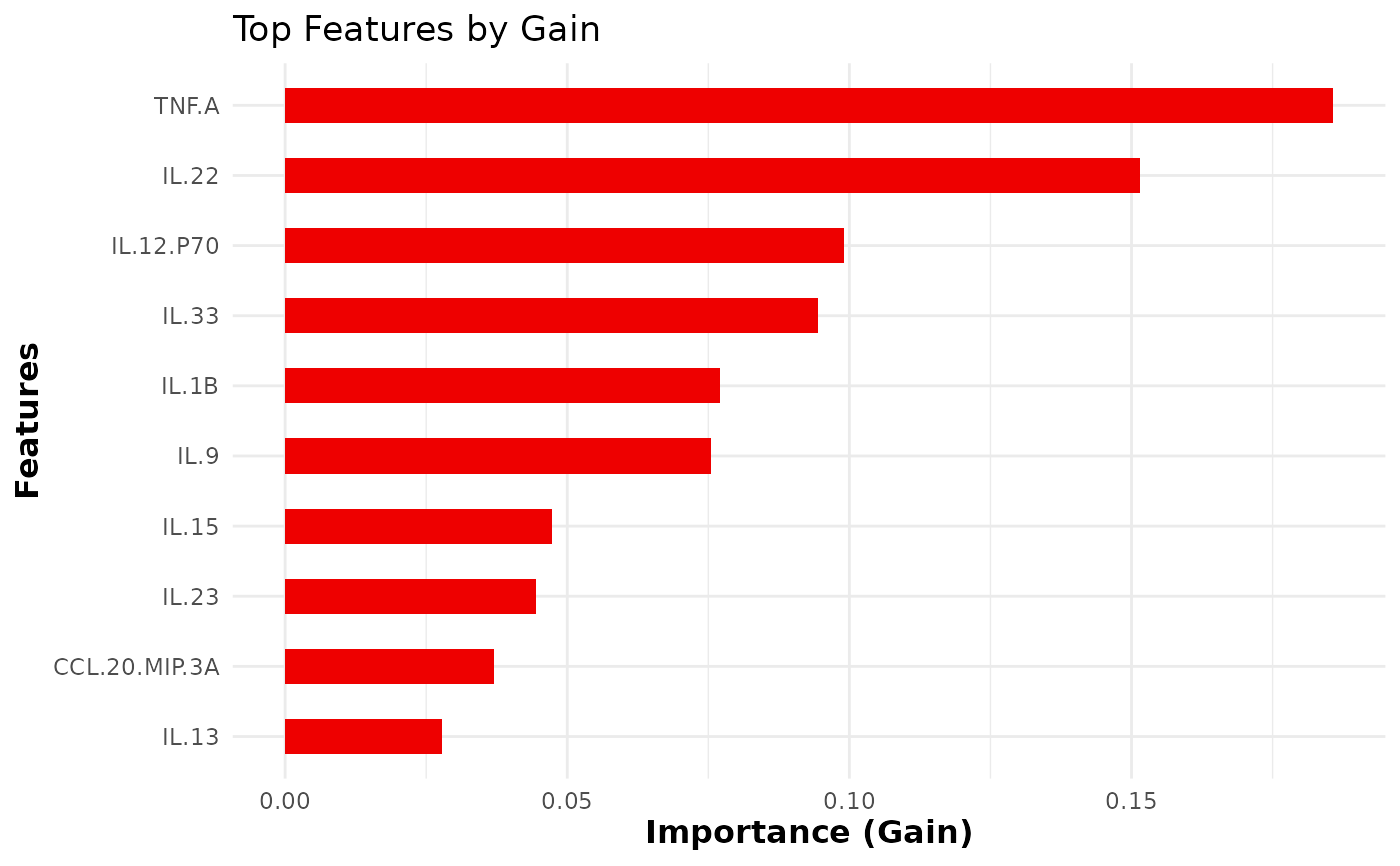
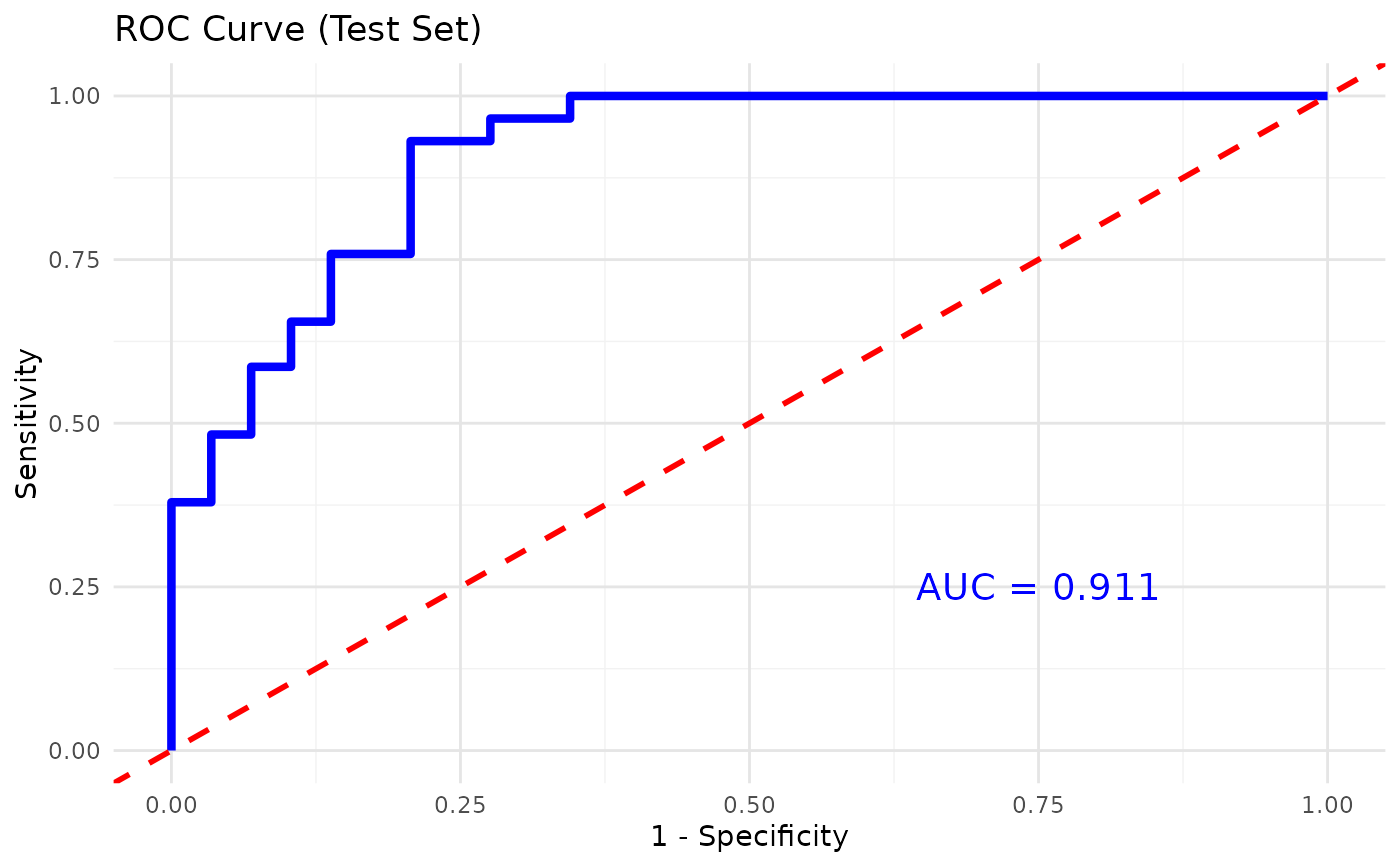
This function trains and evaluates an XGBoost classification model on cytokine data. It allows for hyperparameter tuning, cross-validation, and visualizes feature importance.
Usage
cyt_xgb(
data,
group_col,
train_fraction = 0.7,
nrounds = 500,
max_depth = 6,
learning_rate = 0.1,
nfold = 5,
cv = FALSE,
objective = "multi:softprob",
early_stopping_rounds = NULL,
eval_metric = "mlogloss",
min_split_loss = 0,
colsample_bytree = 1,
subsample = 1,
min_child_weight = 1,
top_n_features = 10,
verbose = 0,
plot_roc = FALSE,
print_results = FALSE,
seed = 123,
scale = c("none", "log2", "log10", "zscore", "custom"),
custom_fn = NULL
)Arguments
- data
A data frame containing numeric predictor variables and one grouping column. Non-numeric predictor columns will be coerced to numeric if possible.
- group_col
Character string naming the column that contains the class labels (target variable). Required.
- train_fraction
Numeric between 0 and 1 specifying the proportion of samples used for model training. The remainder is reserved for testing. Default is 0.7.
- nrounds
Integer specifying the number of boosting rounds. Default is 500.
- max_depth
Integer specifying the maximum depth of each tree. Default is 6.
- learning_rate
Numeric specifying the learning rate. Default is 0.1.
- nfold
Integer specifying the number of folds for cross-validation when
cv = TRUE. Default is 5.- cv
Logical indicating whether to perform cross-validation using
xgb.cv. Default isFALSE.- objective
Character string specifying the objective function. For multi-class classification use "multi:softprob"; for binary classification use "binary:logistic". Default is "multi:softprob".
- early_stopping_rounds
Integer specifying the number of rounds without improvement to trigger early stopping. Default is NULL (no early stopping).
- eval_metric
Character specifying the evaluation metric used during training. Default is "mlogloss".
- min_split_loss
Numeric specifying the minimum loss reduction required to make a further partition. Default is 0.
- colsample_bytree
Numeric specifying the subsample ratio of columns when constructing each tree. Default is 1.
- subsample
Numeric specifying the subsample ratio of the training instances. Default is 1.
- min_child_weight
Numeric specifying the minimum sum of instance weight needed in a child. Default is 1.
- top_n_features
Integer specifying the number of top features to display in the importance plot. Default is 10.
- verbose
Integer (0, 1 or 2) controlling the verbosity of
xgb.train. Default is 0. Larger values print more information.- plot_roc
Logical indicating whether to plot the ROC curve and compute the AUC for binary classification. Default is
FALSE.- print_results
Logical. If
TRUE, prints the confusion matrix, top features and cross-validation metrics to the console. Default isFALSE.- seed
Optional integer seed for reproducibility. Default is 123.
- scale
Character string specifying a transformation to apply to numeric predictors prior to model fitting. Possible values are "none", "log2", "log10", "zscore" or "custom". When set to "custom" a user defined function must be supplied via
custom_fn. Defaults to "none".- custom_fn
A custom transformation function used when
scale = "custom". Ignored otherwise. Should take a numeric vector and return a numeric vector of the same length.
Value
An invisible list with elements: model (the trained
xgboost object), confusion_matrix (test set confusion
matrix), importance (variable importance matrix),
class_mapping (mapping from class names to numeric labels),
cv_results (cross-validation results when cv=TRUE),
importance_plot (a ggplot2 object of the top feature
importance), and roc_plot (a ROC curve for binary
classification when plot_roc=TRUE). All plots are printed
automatically.
Examples
data_df0 <- ExampleData1
data_df <- data.frame(data_df0[, 1:3], log2(data_df0[, -c(1:3)]))
data_df <- data_df[, -c(2:3)]
data_df <- dplyr::filter(data_df, Group != "ND")
cyt_xgb(
data = data_df,
group_col = "Group",
nrounds = 250,
max_depth = 4,
min_split_loss = 0,
learning_rate = 0.05,
nfold = 5,
cv = FALSE,
objective = "multi:softprob",
eval_metric = "auc",
plot_roc = TRUE,
print_results = FALSE)